Summary
In this challenge by @t0xodile - Thomas Stacey we are given the opportunity to play with a CL.0 request smuggling. The technique is very well described, way better that I could do, on PortSwigger academy https://portswigger.net/web-security/request-smuggling/browser/cl-0 and of course in this post by the challenge author himself: https://outpost24.com/blog/http-request-smuggling-to-hijack-user-session/
The hint
Fuzzing or whatever here won’t take you anywhere. There is a subtle hint about what has to be done in /static/sytle.css
* Subtle Falling Code Effect (More subtle than snowflakes) */
body::before {
content: '01001000 01010100 01010100 01010000 00100000 01000100 01000101 01010011 01011001 01001110 01000011 00100000 01000001 01010100 01010100 01000001 01000011 01001011 01010011'; /* Example binary */
}
[...SNIP...]
body::after {
content: '01000010 01010010 01001111 01010111 01010011 01000101 01010010 00101101 01010000 01001111 01010111 01000101 01010010 01000101 01000100 00101110 00101110 00101110'; /* Another example */The binary strings decode respectively to:
HTTP DESYNC ATTACKS
BROWSER-POWERED...
CL.0
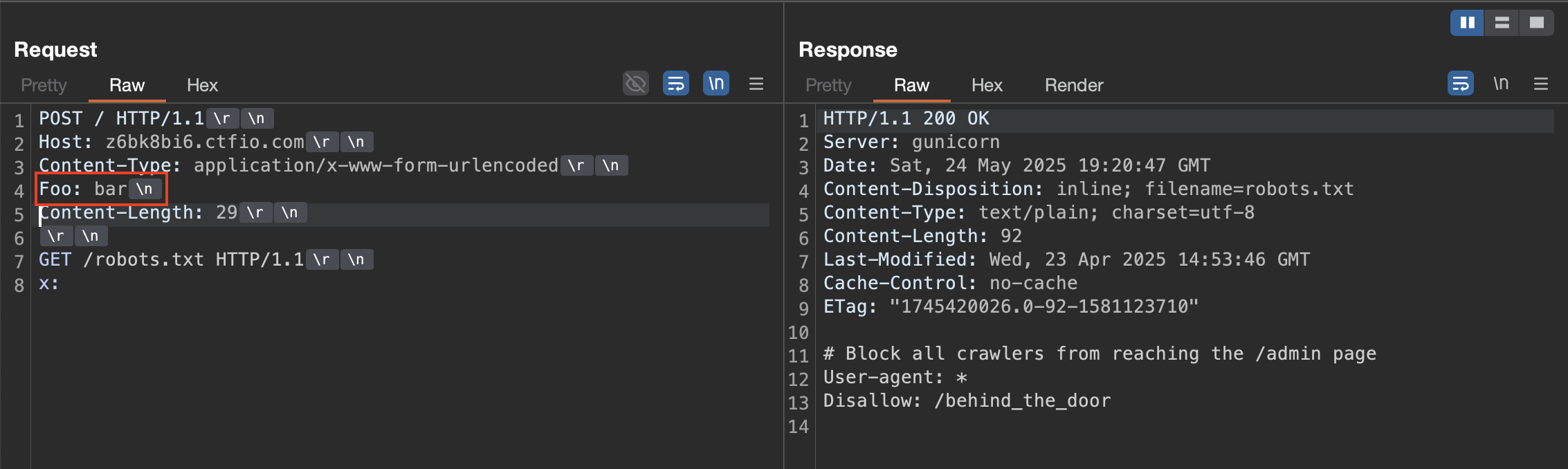
To understand what was happening I used the excellent Burp plugin HTTP Smuggler. A probe reveals what they call a CL.0 desync: badsetupLF|GET /robots.txt. In the following please note that “Update Content-Length” and “Normalize HTTP/1 line endings” are disabled. You have to account for the correct Content-Length for the smuggled request (to /robots.txt in this example, you will have to do for /behind_the_door to get the flag).
The key thing is also the single line feed in the Foo: header, without a carriage return (from this badsetupLF)
Explanation from the author
Someone directly asked the author of the challenge on Discord for an explanation, and here is the answer!
The intended “flow” was to use a tool called “http request smuggler” which detects the CL.0 smuggling vulnerability. The issue the extension reports contains several attache requests, which if you inspect carefully reveal that there is a missing \r on the Foo: bar header. As for why it works… That’s a bit more complicated.
Effectively the frontend and backend disagree on where the request ends because
- the frontend thinks newlines end with just
\n - and the backend thinks that you need
\r\nto have a complete new line.
Therefore, on the backend, Foo: bar\nContent-Length: 29 is treated as one complete header (making the CL header redundant since it’s just in the value of the Foo header. Since the backend therefore can’t see or ignores the Content-length header, it assumes the content length is 0 and progresses the smuggled prefix as the start of a new request, bypassing any frontend access control rules.